Program For Linear Regression With Gradient Descent
I took a Python program that applies gradient descent to linear regression and converted it to Ruby. But first, a recap: we use linear regression to do numeric prediction.
If x is an input (independent) variable and y is an output (dependent) variable, we come up with an initial formula (equation) that shows the mathematical relation between them.
Next we take each value of x and calculate the value of y using our initial equation. The difference between the calculated value of y and the actual y value corresponding to the x value is the error. The error values are summed up by which we arrive at another equation. We minimize this equation using the gradient descent algorithm so that we come up with the best fit equation.

When I was searching the web on this topic, I came across this page “An Introduction to Gradient Descent and Linear Regression” by Matt Nedrich in which he presents a Python example. The program finds the best fit line for a given data set of x and y values. Good catch for me. For practice, I took Matt’s program and re-wrote it in Ruby.
I liked Matt’s blog article, so I am giving parts of it below but with my Ruby snippets.
Finally, we come to the complete program:
The file "data.cv" required to run this program is available at this -> link.
If x is an input (independent) variable and y is an output (dependent) variable, we come up with an initial formula (equation) that shows the mathematical relation between them.
Next we take each value of x and calculate the value of y using our initial equation. The difference between the calculated value of y and the actual y value corresponding to the x value is the error. The error values are summed up by which we arrive at another equation. We minimize this equation using the gradient descent algorithm so that we come up with the best fit equation.
When I was searching the web on this topic, I came across this page “An Introduction to Gradient Descent and Linear Regression” by Matt Nedrich in which he presents a Python example. The program finds the best fit line for a given data set of x and y values. Good catch for me. For practice, I took Matt’s program and re-wrote it in Ruby.
I liked Matt’s blog article, so I am giving parts of it below but with my Ruby snippets.
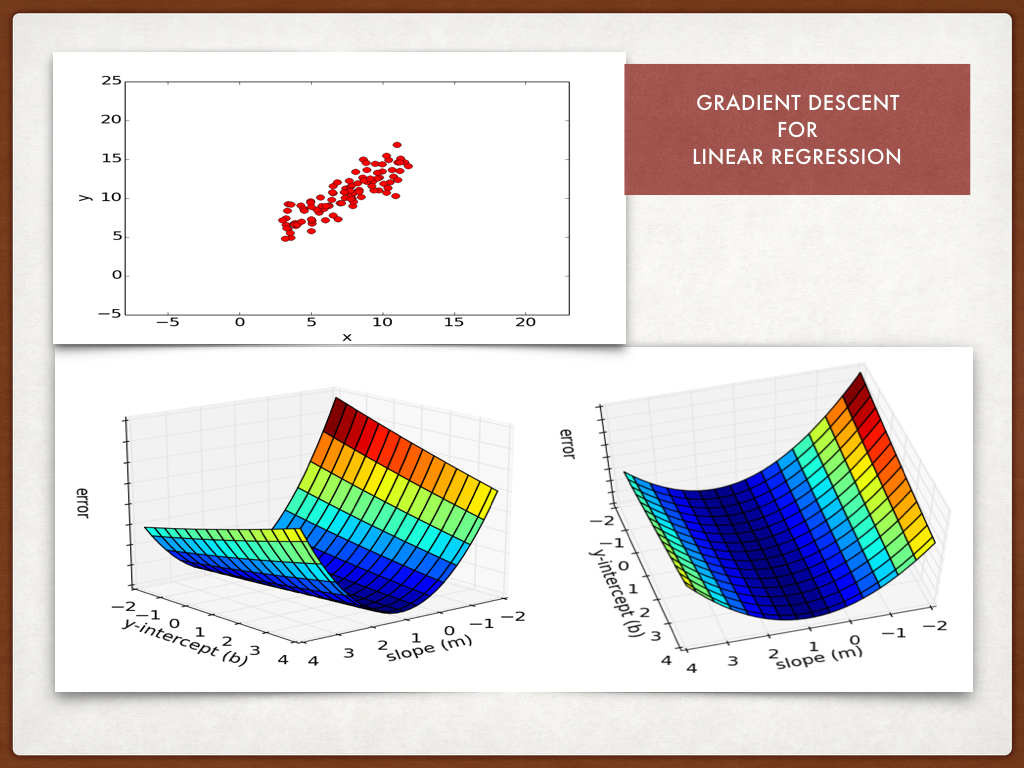
To compute error for a given line, we’ll iterate through each (x, y) point in our data set and sum the square distances between each point’s y value and the candidate line’s y value (computed at mx + b).
Formally, this error function will look like:$$Error_(m,b) = \frac{1}{N}\sum_{i=1}^N(y_i - (mx_i + b ))^2$$
0.upto points.length-1 do |i|
x = points[i][0]
y = points[i][1]
totalError += (y - (m * x + b)) ** 2
end
return totalError / points.length
If we minimize this function, we will get the best line for our data. Since our error function consists of two parameters (m and b) we can visualize it as a two-dimensional surface.
When we run gradient descent search, we will start from some location on this surface and move downhill to find the line with the lowest error. To run gradient descent on this error function, we first need to compute its gradient. The gradient will act like a compass and always point us downhill.
To compute it, we will need to differentiate our error function. Since our function is defined by two parameters (m and b), we will need to compute a partial derivative for each. The derivatives work out to be:$$\frac{\partial}{\partial m} = \frac{2}{N}\sum_{i=1}^N - x_i(y_i - (mx_i + b))$$ $$\frac{\partial}{\partial b} = \frac{2}{N}\sum_{i=1}^N - (y_i - (mx_i + b))$$
0.upto points.length-1 do |i|
x = points[i][0]
y = points[i][1]
m_gradient += -(2/n) * x * (y - ((m_current * x) + b_current))
b_gradient += -(2/n) * (y - ((m_current * x) + b_current))
end
new_m = m_current - (learningRate * m_gradient)
new_b = b_current - (learningRate * b_gradient)


Сізде тамаша мақала бар. Сізге жемісті күн тілейміз
ReplyDeletebon ngam chan
máy ngâm chân giải độc
bồn mát xa chân
chậu ngâm chân giá rẻ
Vanskeligheter( van bi ) vil passere. På samme måte som( van điện từ ) regnet utenfor( van giảm áp ) vinduet, hvor nostalgisk( van xả khí ) er det som til slutt( van cửa ) vil fjerne( van công nghiệp ) himmelen.
ReplyDeleteThanks for the information. Keep sharing.
ReplyDeleteMachine Learning training in Pallikranai Chennai
Data science training in Pallikaranai
Python Training in Pallikaranai chennai
Bigdata training in Pallikaranai chennai
Spark with ML training in Pallikaranai chennai